
Meaning of Chaos Engineering
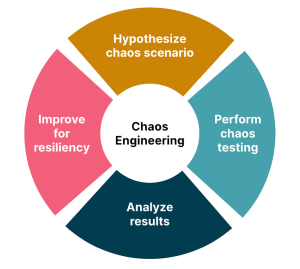
Chaos Engineering is a discipline aimed at increasing the resilience of distributed systems through controlled experiments. The core idea is to intentionally inject failures or disturbances into a system to uncover weaknesses, bottlenecks, or vulnerabilities before they cause significant issues in a real-world scenario. By doing so, organizations can proactively identify and address potential points of failure, thereby improving their systems’ overall reliability and robustness. These experiments are typically conducted in production-like environments and follow a systematic approach to ensure that the impact on users and the business is minimized.
The goal is not to create chaos for its own sake but rather to build confidence in the system’s ability to withstand unexpected events and maintain acceptable levels of performance and functionality. Chaos Engineering is closely related to concepts such as fault tolerance, resilience engineering, and system reliability. It has gained popularity in recent years, particularly in organizations with complex, highly distributed architectures, such as those utilizing microservices or cloud-based infrastructure.
History of Chaos Engineering
The roots of chaos engineering can be traced back to a few different sources, but the term itself and the modern practice we know today emerged in the late 2000s. Here’s a timeline of some key events:
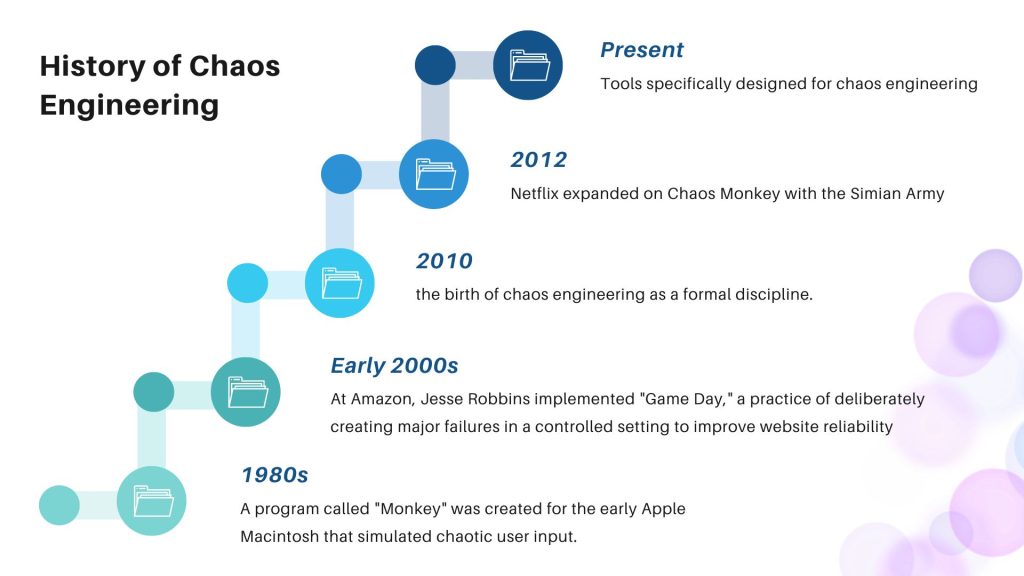
- Early Inspiration (1980s): While not exactly chaos engineering, a program called “Monkey” was created for the early Apple Macintosh that simulated chaotic user input. This playful experiment foreshadows the core idea of injecting randomness to test system robustness.
- Game Day at Amazon (Early 2000s): At Amazon, Jesse Robbins implemented “Game Day,” a practice of deliberately creating major failures in a controlled setting to improve website reliability. This approach drew inspiration from how firefighters train.
- Chaos Monkey at Netflix (2010): This is generally considered the birth of chaos engineering as a formal discipline. Facing the challenges of a complex cloud-based architecture with microservices, Netflix engineers created Chaos Monkey, a tool that randomly terminated virtual machines to test how the system would respond to such failures.
- The Simian Army and Open Source (2012): Netflix expanded on Chaos Monkey with the Simian Army, a suite of tools to inject various failures and simulate different types of disruptions [Wikipedia: Chaos Engineering]. In 2012, they open-sourced Chaos Monkey, allowing others to adopt this approach.
- The Rise of Chaos Engineering: Since then, chaos engineering has become a recognized practice for building more resilient systems. New companies offer tools specifically designed for chaos engineering, and the “Chaos Engineer” role has become more prominent.
Principles of Chaos Engineering
Chaos engineering relies on a set of core principles to guide its experiments and ultimately build confidence in a system’s ability to handle disruptions. Here are some key principles:
Understanding Steady-State Behavior:
- Define how the system should behave under normal conditions. This establishes a baseline for comparison when you introduce failures.
- Focus on measurable outputs rather than internal system functions.
Simulating Real-World Events:
- Design experiments that mimic real-world failures, like disk outages, network issues, or spikes in traffic.
- This helps identify weaknesses that might not be apparent in ideal circumstances.
Running Experiments in Production:
- While it might seem counter-intuitive, chaos engineering experiments are often run directly in production environments.
- This allows you to see how the system behaves under real-world load and configurations.
Automating and Minimizing Impact:
- Automate experiments to ensure they run regularly and catch potential issues before they cause problems.
- Minimize the “blast radius” of your experiments. This means isolating the affected components to avoid impacting the entire system or causing unnecessary disruption for users.
Here are some additional advanced principles you might encounter:
- Hypothesis-driven: Each experiment should test a specific hypothesis about how the system will react to a particular failure.
- Continuous Improvement: Chaos engineering is an ongoing process. Regularly iterate on your experiments and adapt them as your system evolves.
By following these principles, chaos engineering empowers you to proactively build fault tolerance and resilience into your systems.
User Personas Involved:
DevOps Engineers: These professionals are often responsible for deploying and maintaining software systems. They use chaos engineering to validate system resilience and identify potential points of failure.
Site Reliability Engineers (SREs): SREs focus on ensuring the reliability and performance of systems. They use chaos engineering to proactively identify and mitigate potential issues before they impact users.
Software Engineers: Engineers involved in building and maintaining software applications also benefit from chaos engineering. They use it to understand how their code behaves under different failure scenarios and to design more resilient software.
System Architects: Architects design the overall structure of systems and applications. They use chaos engineering to validate their architectural decisions and ensure that systems can handle failures gracefully.
Unlock Chaos Engineering powers with NetHavoc
NetHavoc offers a wide variety of chaos experiments across infrastructure, network, and application levels. In-built integration with Cavisson’s cutting-edge performance testing and observability solution makes it as simple as a matter of clicks to analyze the impact of chaos experiments with a production-level load on end-user experience by capturing actual user sessions and viewing the performance of your application.
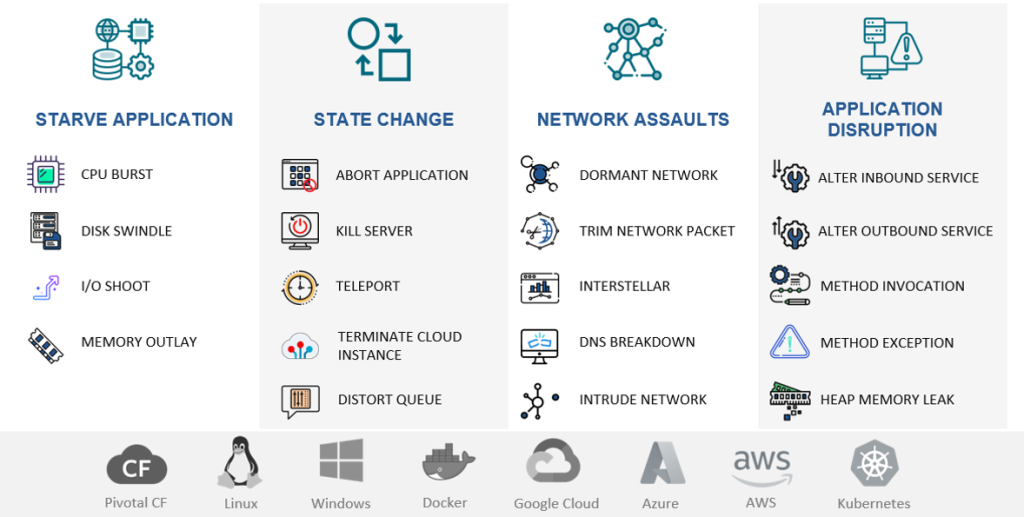
With support for chaos experiments across different components of an application ecosystem like infrastructure, network, application code and messaging queues, NetHavoc provides the most comprehensive coverage for organizations looking to ensure resiliency in all different aspects of their business critical applications.
Conclusion
In today’s dynamic IT landscape, where resilience is paramount, chaos engineering emerges as a powerful ally for businesses striving to fortify their systems against unforeseen disruptions. By embracing chaos engineering principles and practices, organizations can shift from a reactive stance to a proactive one, systematically identifying and addressing vulnerabilities before they escalate into crises.
As businesses navigate the complexities of distributed systems and cloud-based architectures, the need for resilience becomes non-negotiable. Chaos engineering empowers teams to simulate real-world scenarios, validate architectural decisions, and continuously improve system robustness. From DevOps engineers to system architects, each stakeholder benefits from the insights gained through chaos engineering experiments.
With solutions like Cavisson unlocking the potential of chaos engineering, businesses can inject controlled disruptions, design complex scenarios, and monitor performance in real time. By embracing chaos, organizations can transform uncertainty into opportunity, ensuring that when chaos strikes, they are not only prepared but poised to thrive in the face of adversity.
Contact us today to kickstart your Chaos Engineering journey.