Enhancing Resilience in Complex System
In an era where digital systems power much of our daily lives, ensuring their reliability and resilience is paramount. Chaos Engineering emerges as a methodology to proactively identify weaknesses
in complex systems before they become critical failures. It involves deliberately injecting faults and disturbances into a system to observe how it
responds, thereby uncovering vulnerabilities and enhancing overall resilience.
This blog serves as a primer for organizations and teams by exploring the benefits, best practices and challenges in chaos engineering to better equip them in their journeytowards building resistance to failure.
Benefits of Chaos Engineering:
- Identifies System Weaknesses: Chaos engineering helps uncover vulnerabilities in a system before they can be exploited or cause system failure.
- Increases System Resilience: By intentionally introducing failures, chaos engineering strengthens the system’s ability to withstand turbulent conditions.
- Improves Customer Satisfaction: Enhanced system resilience reduces downtime, improving the user experience.
- Facilitates Proactive Problem Solving: It allows teams to proactively address potential issues rather than reacting to them post-occurrence.
- Enhances Understanding of the System: Chaos engineering provides deeper insights into the system’s behavior under stress.
Best Practices:
Chaos engineering requires carefully integrating some best practices to ensure experiments run smoothly and provide insights into system behavior under chaotic conditions.![]()
![]() Gradually scale up your experiments: Start with a smaller component of your system and introduce a minor disruption with little impact. As you gain confidence, gradually expand your experiments, increasing the complexity and intensity of the disruptions.
Gradually scale up your experiments: Start with a smaller component of your system and introduce a minor disruption with little impact. As you gain confidence, gradually expand your experiments, increasing the complexity and intensity of the disruptions.![]()
![]() Focus on critical parts: During the hypothesis creation phase, it is critical to prioritize critical system components and develop specific, realistic hypotheses.
Focus on critical parts: During the hypothesis creation phase, it is critical to prioritize critical system components and develop specific, realistic hypotheses.![]()
![]() Accept failures: If an experiment fails, it is critical to avoid discouragement and instead view it as a learning experience. Be willing to fail and learn from your mistakes.
Accept failures: If an experiment fails, it is critical to avoid discouragement and instead view it as a learning experience. Be willing to fail and learn from your mistakes. ![]()
![]() Measure and monitor everything: Chaos experiments should produce metrics that reveal the impact of those experiments. These measurements help you understand how systems behave under abnormal conditions and provide valuable insights into areas for improvement.
Measure and monitor everything: Chaos experiments should produce metrics that reveal the impact of those experiments. These measurements help you understand how systems behave under abnormal conditions and provide valuable insights into areas for improvement.![]()
![]() Automate the experiments: Chaos experiments should be automated as much as possible, enabling rapid and continuous execution of repeated experiments while minimizing the need for manual, labor-intensive processes.
Automate the experiments: Chaos experiments should be automated as much as possible, enabling rapid and continuous execution of repeated experiments while minimizing the need for manual, labor-intensive processes.![]()
![]() Incorporate what you have learned: Chaos engineering experiments lead to important discoveries about previously unknown system behaviors. These experiments can demonstrate necessary changes in system architecture. Provide insights into the resilient strategies that should be implemented within the system. Incorporating this valuable knowledge into decision-making processes can help to develop more resilient systems.
Incorporate what you have learned: Chaos engineering experiments lead to important discoveries about previously unknown system behaviors. These experiments can demonstrate necessary changes in system architecture. Provide insights into the resilient strategies that should be implemented within the system. Incorporating this valuable knowledge into decision-making processes can help to develop more resilient systems.![]()
![]() Involve all parties concerned: Chaos engineering is a collaborative effort — it is essential to involve all concerned parties, including product managers, developers, and operations engineers, throughout the process. It offers everyone mutual understanding and helps meet their expectations.
Involve all parties concerned: Chaos engineering is a collaborative effort — it is essential to involve all concerned parties, including product managers, developers, and operations engineers, throughout the process. It offers everyone mutual understanding and helps meet their expectations.
Challenges:
- Safety Concerns: Introducing controlled chaos into production environments carries inherent risks and requires careful planning to minimize the potential impact on users.
- Complexity: Managing chaos experiments in highly distributed and interconnected systems can be challenging, requiring sophisticated tooling and coordination.
- Organizational Resistance: Some stakeholders may be resistant to the idea of intentionally disrupting systems, necessitating education and buy-in at all levels of the organization.
- Resource Intensive: Implementing Chaos Engineering practices requires investment in tooling, training, and dedicated resources, which may be a barrier for some organizations.
- Measuring Impact: Assessing the effectiveness of chaos experiments and quantifying improvements in system resilience can be difficult, requiring careful analysis of both quantitative and qualitative data.
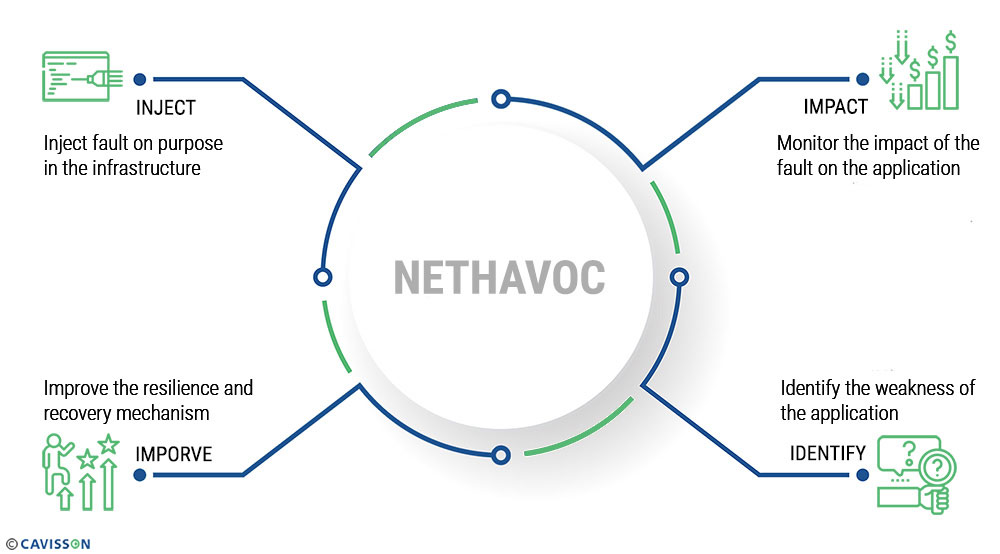
Enhancing Reliability with NetHavoc, Cavisson’s Chaos Engineering Platform
NetHavoc is tailored to aid organizations in assessing their system’s resilience by mimicking real-world failures. This ensures their systems can endure such events, mitigating potential disruptions. Cavisson’s Chaos Engineering Platform offers a comprehensive solution to fortify your entire application ecosystem against unforeseen failures and disruptions. Here’s how:
- Strengthen Resilience Posture: By simulating real-world failure scenarios across different components like network, infrastructure & application code, NetHavoc is ideal to identify readiness loopholes and help organizations strengthen resilience of critical application components.
- Reducing Uncertainties: Systematically inducing failures provides empirical data to reduce uncertainties and enhance predictability of system performance.
- Safeguarding User Experience: Proactively addressing potential breakdowns ensures reliable service delivery, enhancing user trust and loyalty.