
Introduction
For microservices, it’s crucial to conduct resiliency testing to ensure that the system can recover from failures and keep operating as expected. Gartner reports that on average, IT downtime costs $5,600 per minute, with the cost of an hour’s downtime ranging from $140,000 to $540,000 depending on the business. A survey shows that 98% of organizations estimate the cost of a single hour of downtime to be over $100,000, while 81% say it costs over $300,000. Any disruption or downtime in these systems can lead to significant financial losses, damage to the organization’s reputation, and loss of customer trust. This is where Cavisson, a leading enabler for Fortune 100 organizations in their quest towards digital excellence, comes in. One of the key ways in which we help businesses reduce their IT downtime costs is via our chaos engineering tool, NetHavoc. This blog will explore some of the most popular design principles for ensuring resilient microservices based applications and how you can leverage NetHavoc to test their effectiveness.
What is resiliency testing?
System downtime is no longer an option. If a user is unable to access an application once, they are unlikely to use it again. Resilience is the system’s ability to gracefully handle and recover from such failures while still providing an acceptable level of service to the business. In a nutshell, it assesses the system’s resilience, introduces a flaw, and ensures that the system fully recovers.
What are microservices?
Software architecture style that involves breaking down a large application into a set of smaller, independent services that can be developed, deployed, and maintained separately. Each service typically has a well-defined interface and communicates with other services via lightweight protocols such as HTTP or messaging systems like RabbitMQ or Kafka. Microservices are designed to be highly modular, scalable, and resilient, and are often used in large, complex systems that require a high degree of agility and flexibility. By breaking down an application into smaller, more manageable components, microservices allow developers to make changes and updates to specific parts of the application without affecting the entire system, leading to faster development cycles, better fault tolerance, and easier maintenance.
Popular Design Principles for Resilient Applications
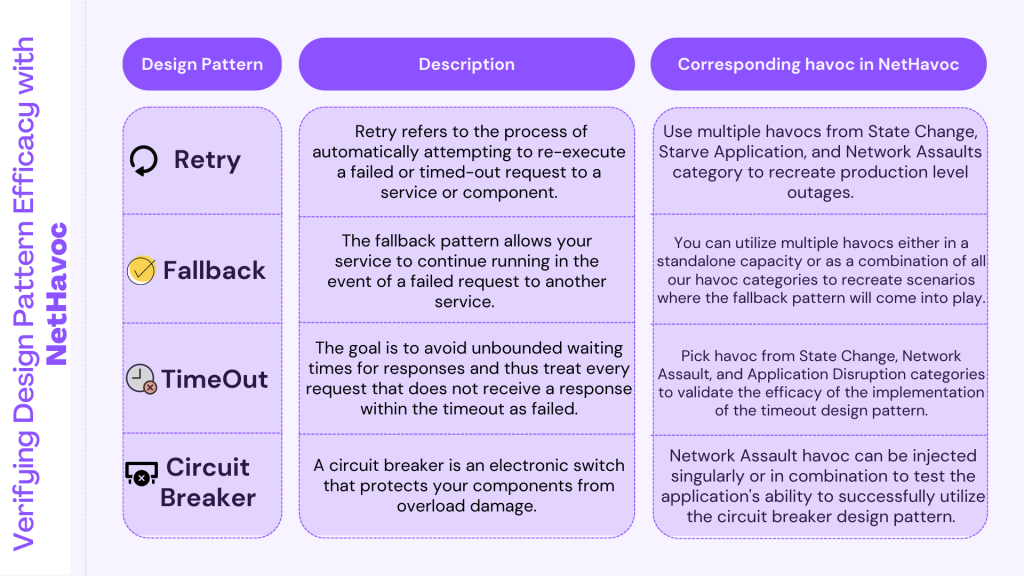
The quest to ensure your applications stay resilient in the face of unknown challenges and outages begins at the very onset of application development and by inculcating certain design principles while creating your business-critical applications. In this section, we will learn some of these principles and conclude by seeing how NetHavoc, Cavisson’s next-generation chaos engineering tool, can assist organizations in understanding how resilient their applications are. Let us go through some of the popular design principles that you can use while developing your application(s):
Retry
When we believe that an unexpected response – or no response at all – can be fixed by sending the request again, the retry pattern can be useful. It is a simple pattern in which failed requests are retried a configurable number of times before the operation is marked as a failure.
The picture below depicts the payment service attempting to issue a fraud check. Due to an internal server error in the fraud check service, the first request fails. The payment service tries again and receives the response that the transaction is not fraudulent.
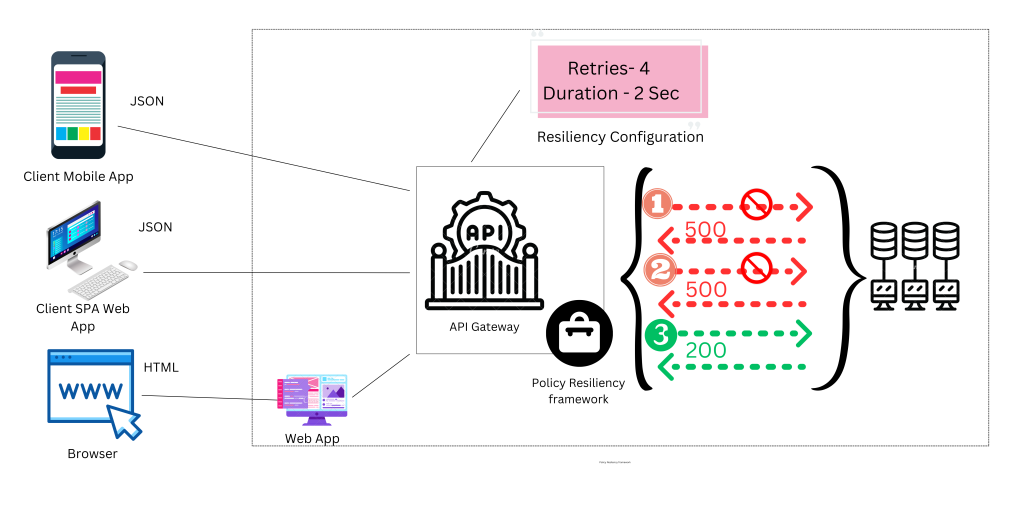
Retries can be useful when there are temporary network issues, such as packet loss. Internal errors of the target service, such as those caused by a database outage. Due to a high volume of requests to the target service, there may be no or slow responses. However, if the problems are caused by the target service being overloaded, retrying may exacerbate the situation. Retry can be combined with other techniques such as exponential backoff or a circuit breaker to avoid turning your resilience pattern into a denial-of-service attack.
Fallback
The fallback pattern allows your service to continue running in the event of a failed request to another service. Instead of terminating the computation due to a missing response, we insert a fallback value.
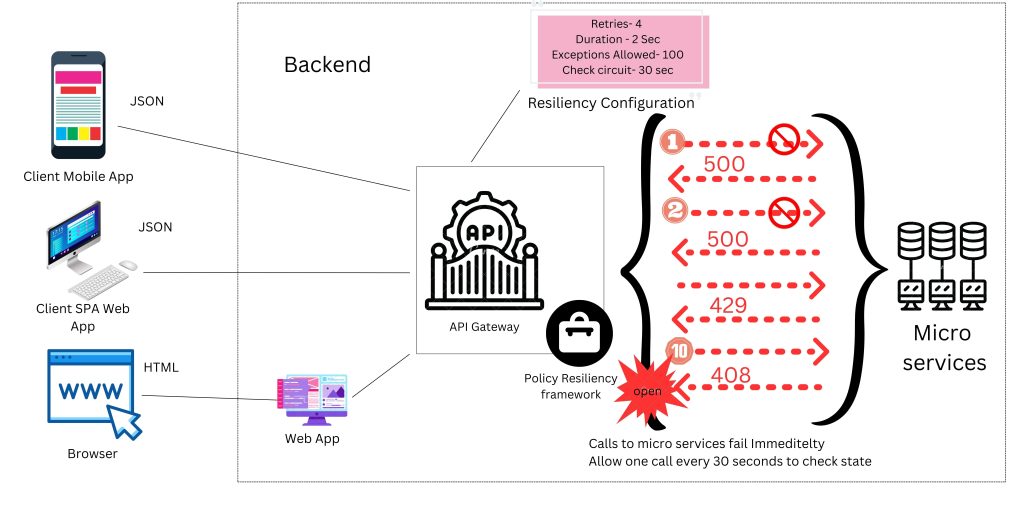
The following image shows the payment service making another request to the fraud check service. The fraud check service returns an internal server error once more. However, this time we have a backup plan in place that assumes the transaction is not fraudulent.
Fallback values are not always possible, but when used correctly, they can greatly increase your overall resilience. In the preceding example, it is risky to treat the transaction as not fraudulent if the fraud check service is unavailable. It even creates an attack surface for fraudulent transactions that attempt to spam the service before attempting to place the fraudulent transaction.
However, if the fallback is to assume that every transaction is fraudulent, no payment will be made, rendering the fallback essentially useless. A good compromise might be to revert to a simple business rule, such as allowing transactions with a relatively small amount to pass through to strike a good balance between risk and customer retention.
Timeout
The timeout pattern is fairly simple, and many HTTP clients have a default timeout setting. The goal is to avoid unbounded waiting times for responses and thus treat every request that does not receive a response within the timeout as failed.
Timeouts are used in almost every application to prevent requests from becoming stuck indefinitely. However, dealing with timeouts is not easy. Consider an order placement in an online shop. If the order creation was still in progress, you can’t be sure if the order was successfully placed but the response timed out, or if the request was never processed.
Combining the timeout with a retry may result in a duplicate order. If you mark the order as failed, the customer may believe the order did not succeed, but it may have done so and they will be charged. Also, your timeouts should be set high enough to allow slower responses to arrive but low enough to prevent you from waiting for a response that will never arrive.
Circuit Breaker
A circuit breaker is an electronic switch that protects your components from overload damage. A circuit breaker in software prevents spam from reaching your services while they are already partially unavailable due to high load.
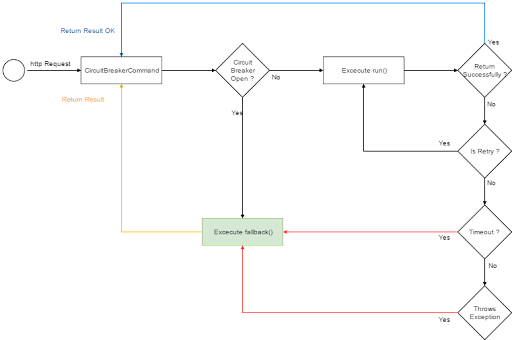
The circuit breaker pattern was described by Martin Fowler. It can be implemented as a stateful software component that alternates between three states: closed (requests flow freely), open (requests are rejected but not submitted to the remote resource), and half-open (requests are rejected but not submitted to the remote resource) (one probe request is allowed to decide whether to close the circuit again). A circuit breaker is demonstrated in the image below.
The request is routed from the payment service to the fraud check service by the circuit breaker. Following two internal server errors, the circuit opens, and subsequent requests are blocked. The circuit eventually switches to a half-open state. It will allow one request to pass in this state and then return to the open state if it fails or close if it succeeds. The circuit is closed again when the next request is successful. Circuit breakers are an effective tool, especially when used in conjunction with retries, timeouts, and fallbacks. Fallbacks can be used not only when a circuit fails, but also when it is open.
NetHavoc - Next Gen Chaos Engineering Tool
NetHavov can aid in the development of resilient microservices-based applications by testing service interactions, validating failover and recovery mechanisms, identifying weaknesses and bottlenecks, and testing scalability. Organizations can make their microservices-based applications more reliable and less prone to failure by utilizing NetHavoc to test how efficiently the design principles discussed above are implemented.
Organizations can make their microservices-based applications more reliable and less prone to failure by utilizing NetHavoc to test how efficiently the design principles discussed above are implemented.
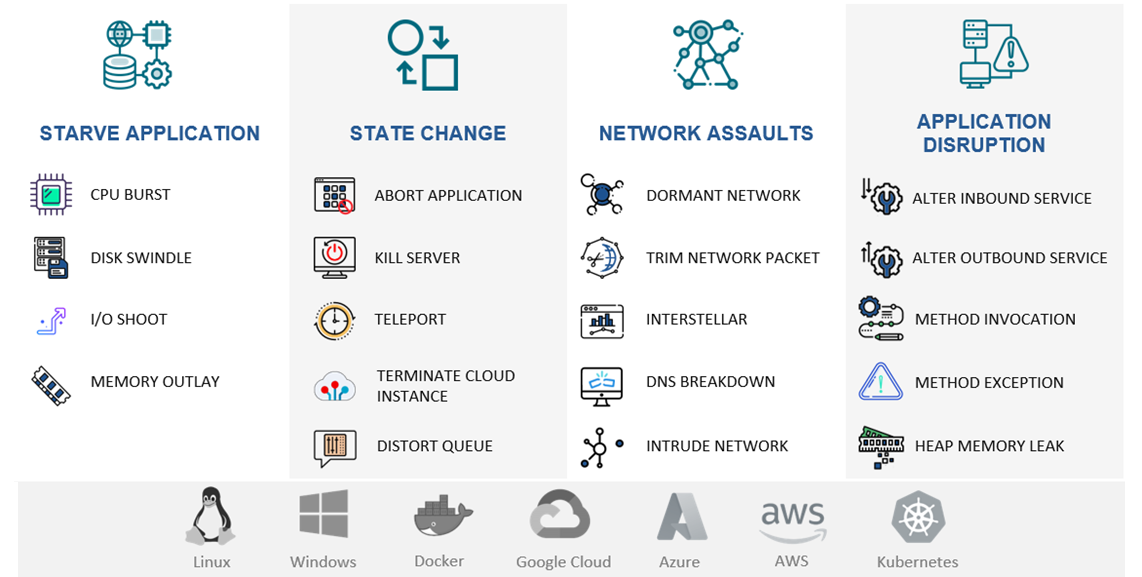
The below infographic shows the different types of chaos experiments or havocs that you can use to test the validity of the different design patterns mentioned above. With NetHavoc, you can combine multiple chaos experiments via Havoc scenarios to comprehensively test microservices, both from an infrastructure and application point of view.
Here are some ways in which using NetHavoc can help make microservices more resilient:
➣ Identifying Weaknesses: By simulating different types of failures such as network failures, resource exhaustion, or application failures, NetHavoc can help identify weaknesses in a microservices architecture. This allows developers to proactively
address these issues before they cause problems in production.
➣ Testing Disaster Recovery: By simulating different types of failures, NetHavoc can also help test disaster recovery plans for microservices. This ensures that the system can recover quickly in the event of failure.
➣ Testing Auto-Scaling: NetHavoc can be used to test how well a microservices architecture can handle auto-scaling. By simulating sudden traffic increases, NetHavoc can help ensure that the system can scale up and down quickly and efficiently.
➣ Increasing Confidence: By using NetHavoc to test the resilience of a microservices architecture, developers can increase their confidence in the system. This allows them to make changes and deploy new features with the knowledge that the system will be able to handle unexpected failures.
Conclusion
To summarize, we discussed what the commonly used design principles are for building resiliency in your applications and how you can leverage Cavisson’s next generation chaos engineering tool, NetHavoc to validate your application’s robustness and its ability to recover from unforeseen issues/challenges/outages.
After all, ensuring exceptional customer experience starts with creating applications with a resiliency first approach and what better way to do so than by leveraging Cavisson’s decades old expertise in the application performance space and our groundbreaking approach that has helped multiple Fortune 100 organizations deliver bespoke online experience.
Visit www.cavisson.com today to schedule a demo with our team and see the benefits of our chaos engineering platform, NetHavoc.