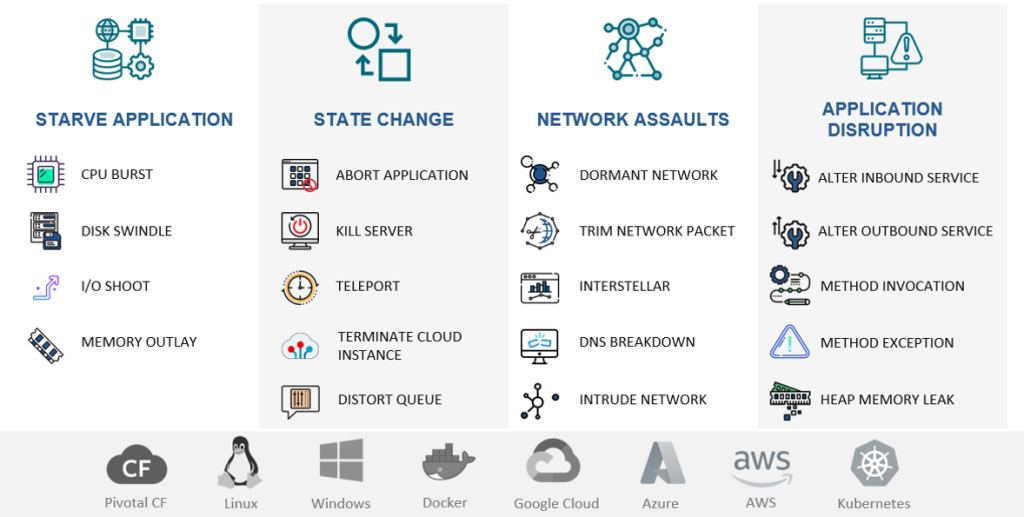
1. Starve Application
Test application resilience by simulating service disruptions including:
- Sudden service crashes and unexpected terminations
- Graceful and ungraceful restarts
- Service unavailability and timeout scenarios
- Dependency service failures
![]() Why It Matters: Application crashes are inevitable. NetHavoc helps ensure your orchestration platform detects failures quickly, restarts services automatically, and maintains service availability through redundancy.
Why It Matters: Application crashes are inevitable. NetHavoc helps ensure your orchestration platform detects failures quickly, restarts services automatically, and maintains service availability through redundancy.
2. State Changes
Validate system behavior during dynamic conditions:
- Configuration changes and rollbacks
- State transitions and environmental modifications
- Feature flag toggles and canary deployments
- Database schema migrations
![]() Why It Matters: Modern systems constantly evolve. Testing state changes ensures deployments don’t introduce instability and that rollback procedures work when needed.
Why It Matters: Modern systems constantly evolve. Testing state changes ensures deployments don’t introduce instability and that rollback procedures work when needed.
3. Network Assaults
Inject network-related failures—the leading cause of production incidents:
- Latency injection (simulating slow networks)
- Packet loss and corruption
- Bandwidth throttling and restrictions
- DNS failures and connectivity issues
- Network partitioning (split-brain scenarios)
![]() Why It Matters: Distributed systems live and die by network reliability. NetHavoc’s network chaos experiments validate that timeout configurations, retry policies, and circuit breakers function correctly.
Why It Matters: Distributed systems live and die by network reliability. NetHavoc’s network chaos experiments validate that timeout configurations, retry policies, and circuit breakers function correctly.
4. Application Disruptions
Test application-level resilience:
- Third-party API failures and slowdowns
- Database connection issues
- Cache failures and invalidation
- Integration point breakdowns
![]() Why It Matters: Applications rarely fail in isolation. NetHavoc ensures your systems gracefully degrade when dependencies experience issues.
Why It Matters: Applications rarely fail in isolation. NetHavoc ensures your systems gracefully degrade when dependencies experience issues.
Precision Chaos: NetHavoc’s Havoc Types

➣ CPU Burst: Performance Under Pressure
Simulate sudden CPU consumption spikes to validate:
- Auto-scaling policies and thresholds
- Resource limit configurations
- Application performance degradation patterns
- Priority-based workload scheduling
Use Case: E-commerce platforms can test whether checkout services maintain performance when recommendation engines consume excessive CPU during traffic spikes.
➣ Disk Swindle: Storage Exhaustion Testing
Fill disk space to verify:
- Monitoring alert triggers and escalation
- Log rotation and cleanup policies
- Application behavior at storage capacity
- Disk quota enforcement
Use Case: Prevent the common “disk full” production disaster by ensuring applications handle storage exhaustion gracefully and monitoring alerts fire before critical thresholds.
➣ I/O Shoot Up: Disk Performance Bottlenecks
Increase disk I/O to identify:
- I/O bottlenecks affecting application performance
- Database query performance under stress
- Logging system impact on applications
- Storage system scalability limits
Use Case: Database-heavy applications can validate that slow disk I/O doesn’t cascade into application-wide slowdowns.
➣ Memory Outlay: RAM Utilization Stress
Increase memory consumption to test:
- Memory management and garbage collection efficiency
- Out of Memory (OOM) killer behavior
- Application memory leak detection
- Container memory limit handling
Use Case: Ensure Kubernetes automatically restarts memory-leaking containers before they affect other workloads on the same node.