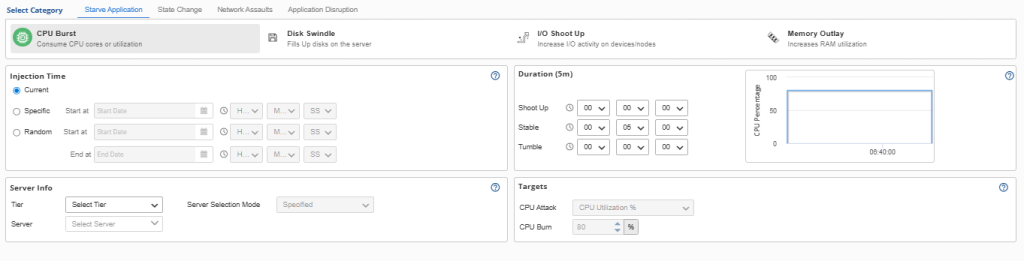
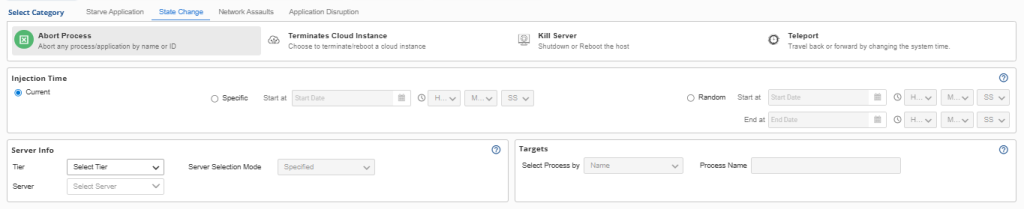
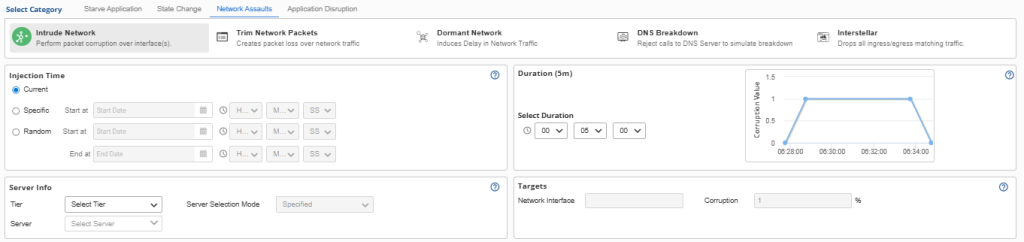
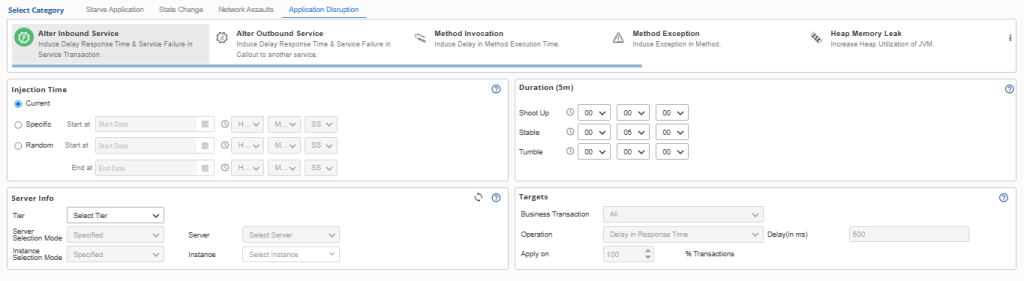
Real-world examples:
– Microsoft Azure’s 2019 global authentication outage resulted from a memory leak in their authentication services, affecting millions of users worldwide. Netflix, a pioneer in chaos engineering, regularly employs these techniques to validate their resilience strategies, proving that proactive application-layer testing prevents customer-facing incidents.
Why Injecting Havoc is Non-Negotiable
– Downtime costs money: For e-commerce giants, even a few minutes of downtime can cost millions.
– Weak links exist everywhere: From expired certificates to slow DNS, every layer is a potential failure point.
– Preparedness beats firefighting: Simulating chaos empowers teams to handle real incidents confidently.
✅ Key Takeaway: Injecting havoc isn’t about destruction—it’s preparation. It transforms uncertainty into resilience and ensures that when failure strikes, your business keeps running.
Conclusion: From Fragile to Antifragile
Every organization will experience system failures—this is a certainty, not a possibility. The choice lies in how you encounter these failures: reactively, when they surprise you at the worst possible moment, or proactively, when you’re prepared with knowledge, tools, and experience.
Chaos engineering transforms your relationship with failure from adversarial to collaborative. Instead of fearing the unknown, you systematically explore it. Instead of hoping your systems will survive pressure, you know they will because you’ve tested them. Instead of learning about your system’s limitations during customer-impacting incidents, you discover them in controlled environments where learning comes without consequences.
Your competitors are already experiencing chaos in their systems—they just don’t realize it yet. The organizations that will dominate tomorrow’s markets aren’t just building faster features; they’re building systems that get stronger under stress. They’re not just preparing for failure; they’re learning to transform it into competitive advantage.
The future belongs to organizations brave enough to break their own systems before the world breaks them. The question that remains is simple: will you choose to experience chaos on your terms, or will you wait for it to choose you?
Ready to transform your approach to system reliability? Cavisson Systems’ NetHavoc platform empowers organizations to build resilience through intelligent chaos engineering strategies. Discover how NetHavoc can help you turn controlled failure into your competitive advantage—because the strongest systems are those that have learned to thrive in chaos.
Ready to Get Started?
Schedule a demo of NetHavoc today and embark on a journey towards unparalleled reliability and peace of mind. Embrace chaos engineering with NetHavoc and build a resilient future for your applications. Contact us now to learn more!