
Your test suite passed. All green. Then production broke.
Sound familiar? It happens because most test suites are written by developers imagining how users will behave — not by watching what users actually do. The gap between those two things is where bugs live, where performance degrades unnoticed, and where your most critical edge cases go untested until a real customer hits them.
At Cavisson, we believe the next evolution of software quality isn’t writing more tests by hand. It’s letting real user behaviour write your tests for you.
The Problem with Manually Designed Tests
Traditional test strategies start from the inside out. Engineers design test cases based on requirements documents, functional specs, or intuition. They mock dependencies, seed databases, and simulate user actions — always working from an assumption of what production looks like.
The result? Tests that validate the happy path beautifully, while your most valuable edge cases remain invisible until a customer finds them.
It’s not a failure of effort. Developers write the tests they can imagine. The problem is that imagination has limits, and production doesn’t respect them.
Consider what consistently gets missed:
- Unusual input combinations that no developer thought to test — because no developer anticipated that a user would combine a partially redeemed gift card with a split-payment method and an address flagged for fraud review, all in the same checkout session.
- Timing-dependent bugs that only surface under real-world concurrency — race conditions that vanish in a controlled test environment but reliably appear when thousands of users hit the same endpoint at the same moment.
- Long-tail workflows that power users rely on but QA never documented — the sequence of seven actions that unlocks a niche feature, repeated daily by a small cohort whose experience quietly breaks after a refactor nobody flagged.
- Performance regressions that only show up at scale — a database query that runs in 12ms in staging and 1.2 seconds in production, because staging never has 50,000 concurrent sessions fighting for connection pool slots.
- Negative and edge cases that human test authors skip — not out of negligence, but because the combinatorial space of what users can do is simply too large for any team to enumerate manually.
Meanwhile, your production environment is generating rich, precise, honest data about exactly how your application behaves under real load — and most teams throw it away.
Starting Where Users Actually Are: Real User Monitoring
Before you can turn real sessions into tests, you need to capture them — accurately, completely, and at scale. This is where Cavisson’s Real User Monitoring (RUM) capabilities form the essential foundation.
RUM instruments your application to record what real users actually do: every page interaction, every API call, every navigation event, every error encountered — in real time, in production, from real devices across real network conditions. Unlike synthetic monitoring, which simulates traffic from predefined scripts written by developers who already know the happy path, RUM captures the full, unfiltered diversity of how your application is actually used.
This distinction matters more than most teams realise.
Synthetic tests are, by definition, limited to what someone thought to write. They’re valuable for confirming known behaviour, but they cannot discover unknown behaviour. RUM can. Because users don’t follow scripts. They arrive from unexpected geographies with unexpected browser configurations. They combine features in sequences no product manager anticipated. They submit inputs that your validation logic has never encountered. They trigger race conditions that only emerge under genuine, unpredictable concurrency. They find the edge cases — not by trying to, but simply by being human and varied and numerous.
Cavisson’s RUM layer captures all of it:
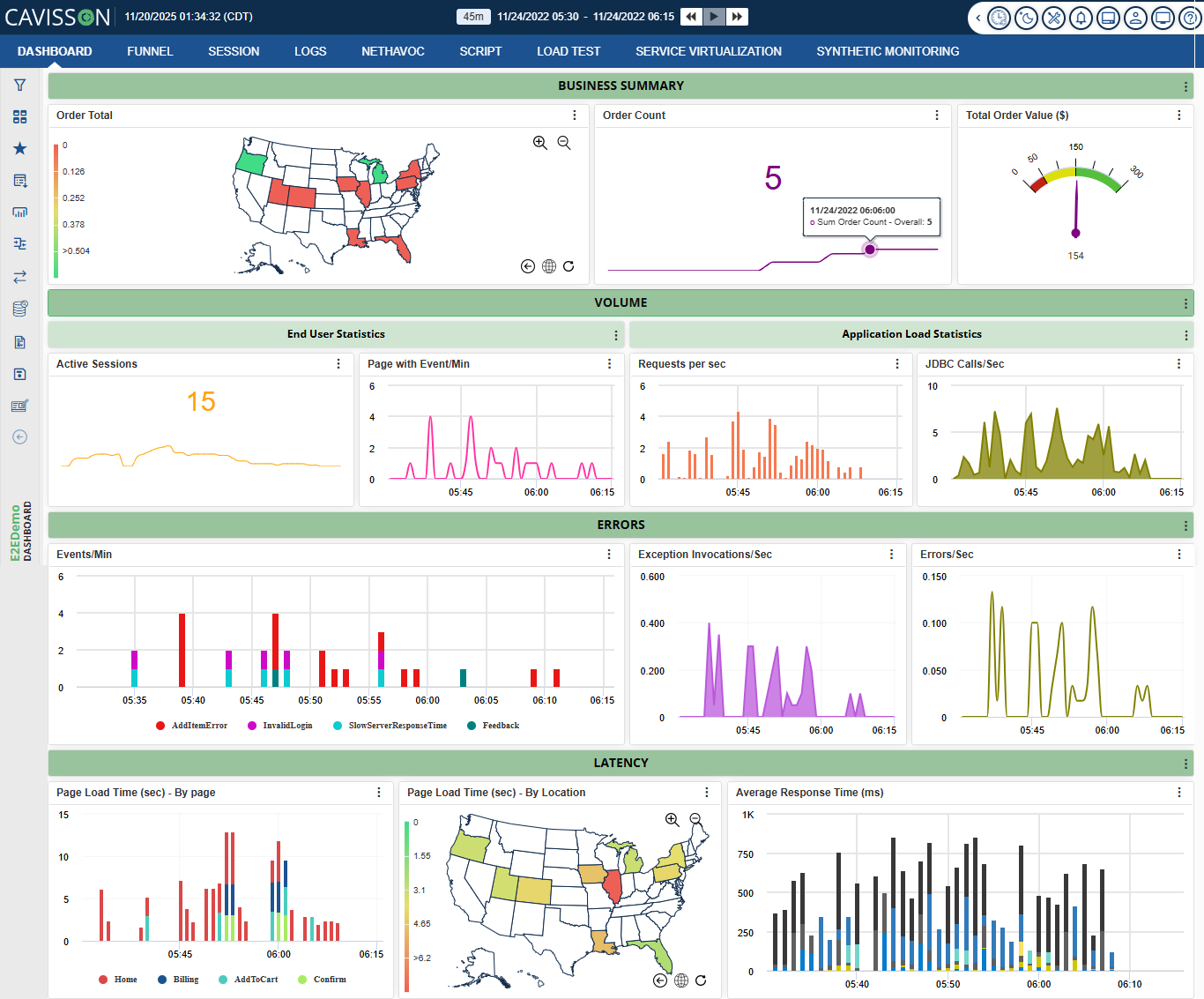
- Distributed traces and spans across your entire stack, mapping every call from frontend to backend to database and back
- Session-level timelines that reconstruct complete user journeys — not individual events in isolation, but the full sequence of what happened and in what order
- Structured logs with full request context, including parameter values, headers, user state, and environmental conditions
- Runtime metrics — latency distributions, error rates, throughput, resource utilisation — that tell you not just what happened, but how it performed under the actual conditions it faced
The result is telemetry that is richer than anything a test author could hand-craft. It includes real parameter values that no developer would have thought to seed into a test fixture. It includes real timing that exposes concurrency bugs invisible in sequential test execution. It includes real failure modes — including the edge cases and negative scenarios that human-driven test creation almost always misses — because real users generated them.
This is the raw material. The next step is turning it into tests.
From Real User Sessions to Tests: The Synthesis Pipeline
Capturing rich real user sessions is step one. Turning them into a living, usable test suite requires three complementary techniques working in sequence.
Session Replay
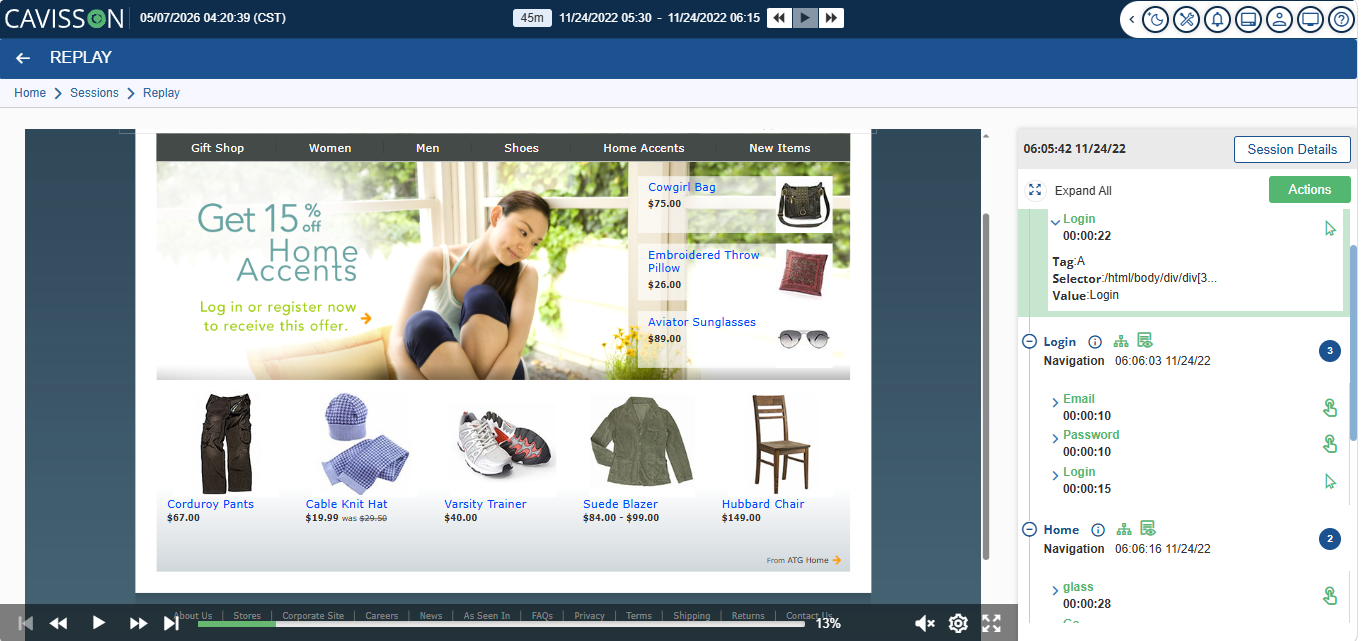
The most direct path from observation to test: take a recorded user session and re-execute it deterministically against a newer version of your application. Compare the outputs. If anything changed that shouldn’t have, you have a regression — caught before it reached production. This sounds straightforward, but doing it well is genuinely hard. Not every session is worth replaying. Not every recorded input is safe to replay as-is. Not every difference in output represents a bug.
Cavisson captures real user sessions using lightweight JavaScript tags for web applications and native SDKs for mobile apps — no heavyweight agents, no intrusive instrumentation. Beyond passive capture, you can define your own custom events to track what matters most to your business: a failure to add an item to cart, an abandoned checkout, a search that returns no results. These events become the signal layer that separates high-value sessions from routine noise.
Once sessions are captured, there are two ways to surface the ones worth turning into tests:
- By journey frequency or rarity — identify the most common paths your users take (ensuring your core flows are always covered) and the rarest ones (the edge cases most likely to slip through). Both extremes deserve tests; the synthesis pipeline finds them automatically.
- By custom events — filter sessions by the specific events you’ve defined. Every session where a user failed to add to cart, hit an error in payment, or triggered an anomaly in a critical journey becomes a direct candidate for test creation. You’re not guessing which sessions matter — your own event definitions tell you.
Cavisson’s replay infrastructure handles the complexity of converting these sessions into executable tests systematically. PII is sanitised from captured sessions before they enter the test pipeline. Near-identical flows are deduplicated, so your CI pipeline isn’t running the same happy-path checkout a hundred times. High-signal sessions — errors, unusually slow paths, novel code coverage, sequences that haven’t been replayed before — are prioritised. The sessions most likely to catch something meaningful get replayed first. You’re not replaying everything. You’re replaying what matters.
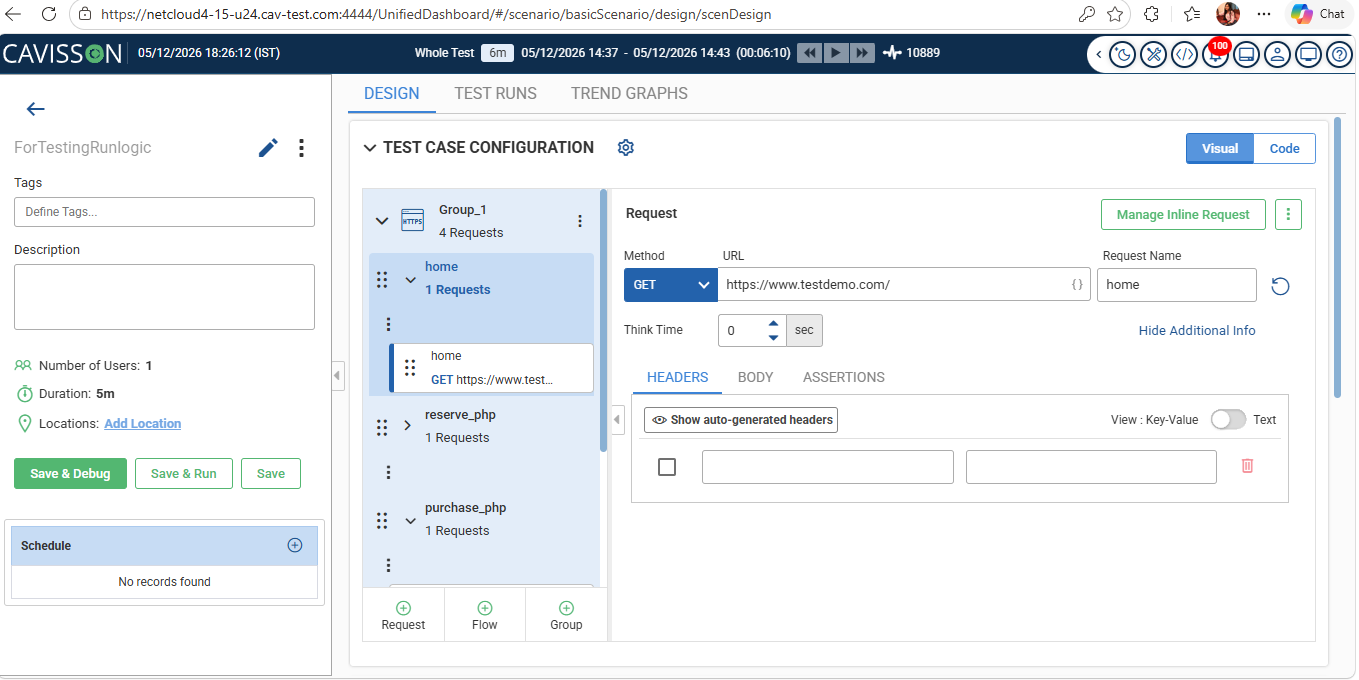
Property Generation/Test Creation
Identifying a valuable session is only half the job — the other half is turning it into a test that can actually run. This is where Cavisson’s AI-powered test generation removes what has traditionally been the most time-consuming step: authoring the test itself.
From a captured session, the AI automatically constructs a complete, executable test — correctly identifying every facet of your application needed to replay the journey faithfully: the target URLs, the UI elements involved, their XPaths, the input values, the navigation sequence, and the expected state at each step. The generated test requires no manual review or adjustment before it can be executed. It goes directly into your CI pipeline and runs.
This matters because the bottleneck in session-to-test workflows is rarely capture — it’s authorship. Recording a valuable user journey takes milliseconds. Writing a test case from it, by hand, takes an engineer hours. Cavisson eliminates that gap entirely: from session to runnable test, automatically, at the scale your production traffic generates.
Auto Assertions
Replay tells you when behaviour changes. Assertion mining tells you what behaviour should be — and encodes that as verifiable, executable assertions. And critically, every assertion is added automatically — your engineers don’t have to write a single one.
By analysing a large corpus of captured production sessions, Cavisson identifies statistical invariants that hold consistently across your real traffic. These aren’t rules someone wrote down. They’re patterns that emerge from evidence:
- “This endpoint always returns a 2xx status when the requesting user holds this role and the resource exists.”
- “This response always completes in under 200ms when the system is under normal load.”
- “This field is never null when this upstream condition is true.”
- “These two operations always appear together — if one succeeds, the other always follows.”
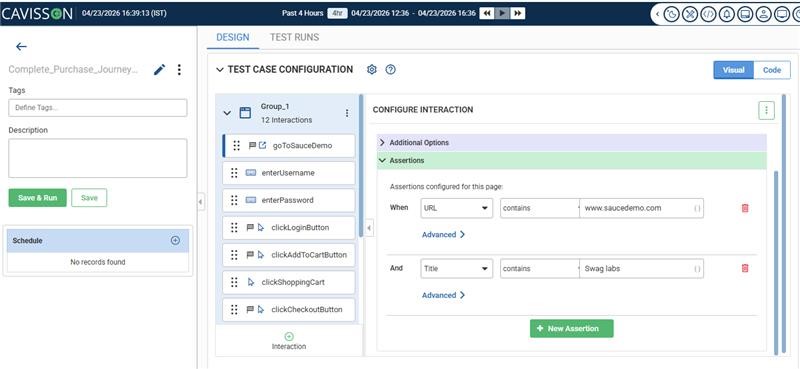
Each of these becomes an assertion in your test suite — automatically generated, grounded in thousands of real observations rather than a developer’s intuition about what the system probably does. No assertion tickets. No test-writing sprints. No coverage gaps because someone forgot to specify the expected behaviour. The assertions write themselves, from evidence your production traffic already provides.
This is particularly powerful for catching negative-case failures. When RUM data shows that a certain error response always includes a specific error code and message structure, that invariant becomes an assertion. When a future release breaks that contract — even in a way nobody thought to test — the assertion catches it.
The Part Most Teams Skip: Closing the Loop
A test suite generated from real sessions is valuable. A test suite that continuously updates as traffic patterns evolve — and that feeds its results back into a smarter observability layer — is transformative. Most teams treat observability and testing as separate concerns operating in separate worlds.
Observability is for production. Testing is for development. Data flows from production into dashboards, and separately, engineers write tests against their understanding of the system.
The two pipelines rarely touch. This separation is where compounding quality debt accumulates. Your observability layer doesn’t know what your tests cover. Your tests don’t know what your users actually do. Both evolve independently, and the gap between them quietly grows.
Cavisson connects them bidirectionally.
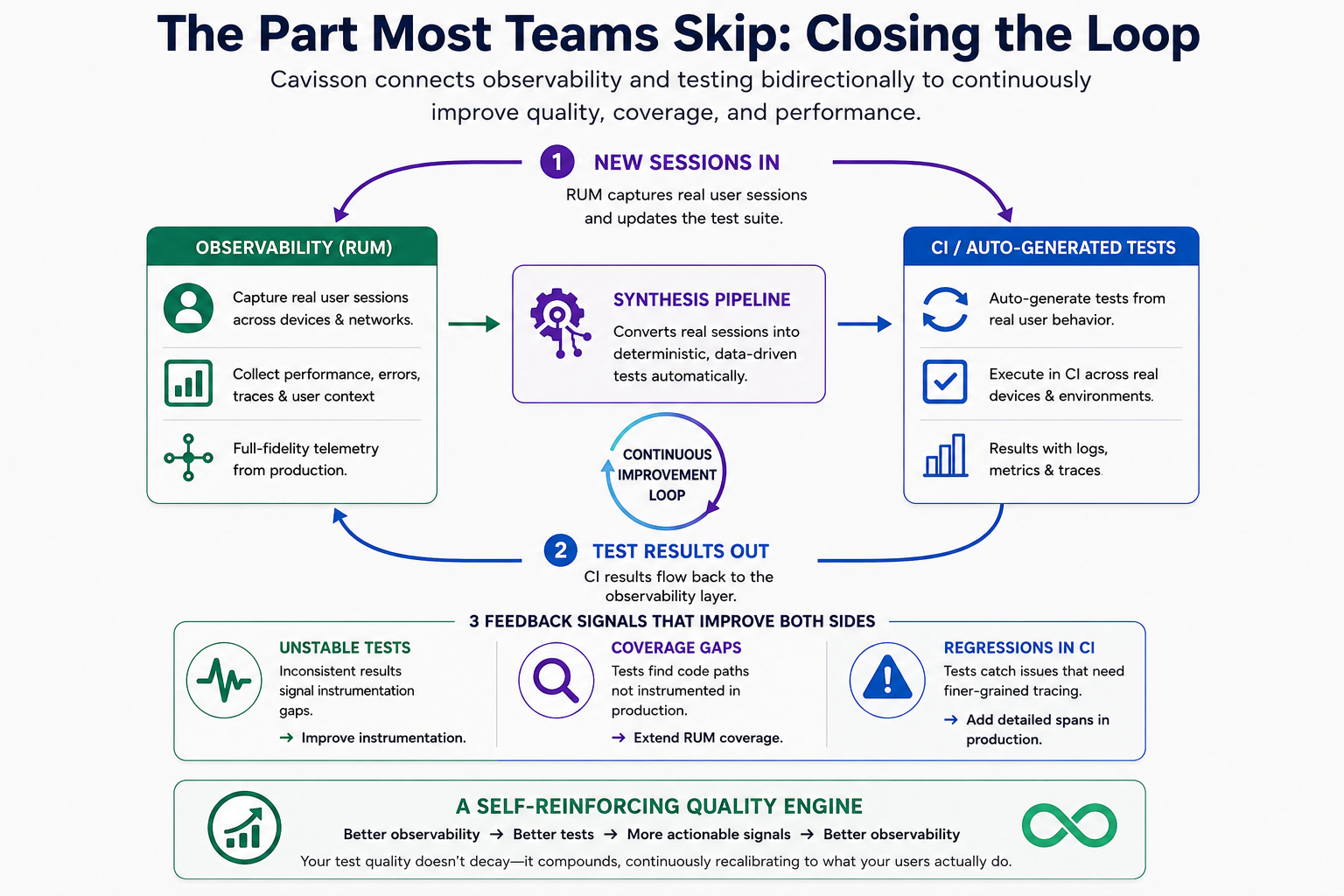
When your RUM layer captures new sessions, they flow into the synthesis pipeline and update your test suite. When CI runs the auto-generated tests, the results flow back into the observability layer:
Unstable tests signal instrumentation gaps — when a replayed session produces inconsistent results across runs, it’s often because the underlying user journey depends on state or timing that RUM isn’t capturing with sufficient fidelity. Rather than suppressing the test, Cavisson surfaces this as a signal to improve instrumentation precision in those specific flows — closing the gap at the source rather than masking it.
Coverage gaps from the test runner highlight application code paths that aren’t instrumented in production — paths that may be exercised by real users but are invisible to your observability layer. That’s a signal to extend RUM coverage.
Regressions caught in CI identify specific production signals that warrant finer-grained tracing. If a test catches a subtle bug in the payment flow, that’s a reason to add more detailed spans to that flow in production — so the next regression is caught even earlier.
Each cycle makes the observability layer more precise, which produces better-targeted tests, which surface more actionable signals, which improve the observability layer further. The loop closes. And rather than your test quality slowly decaying as the codebase drifts away from what the tests cover, it compounds — continuously recalibrating to what your users actually do.
What This Looks Like in Practice
Consider a high-traffic e-commerce platform carrying a familiar burden: the test suite is thorough on paper, CI passes consistently, and yet post-deploy regressions keep surfacing in checkout flows. The engineering team isn’t cutting corners. The flows are simply too complex — too many permutations of cart composition, user geography, loyalty status, discount stacking, and payment method — to mock accurately by hand. No test author could enumerate the combinatorial space. Nobody is expected to.
With Cavisson’s RUM layer capturing real sessions and the synthesis pipeline converting them into tests, the picture changes quickly. Within the first week, hundreds of distinct checkout flows are captured from real production traffic and converted into replay tests. These aren’t flows anyone designed — they’re flows real users took, including sequences that no developer would have thought to test and no QA engineer would have thought to document. Multi-currency carts with mixed discount types. Guest checkout sessions that crossed device boundaries mid-session. Payment retries following a bank-side timeout. All of it, captured and converted.
Assertion mining surfaces invariants across the payment service that the existing test suite never formally specified: conditions that held true across tens of thousands of real transactions but were never written down as assertions, because everyone assumed they were obviously true and didn’t need testing.
They did.
When the first CI run executes the auto-generated suite, it catches a regression in a discount code validation path — one introduced by a routine refactor that touched code everyone assumed was stable. The bug would have shipped three days later. It couldn’t have been caught by the existing suite. Nobody had written a test for that specific combination of discount type, cart state, and user geography. But a real user had followed exactly that path. Cavisson’s RUM layer captured it. The synthesis pipeline turned it into a test. And the test caught what human imagination missed. This is the gap that hand-written test suites cannot close on their own. Edge cases don’t emerge from requirements documents. Negative scenarios don’t appear in functional specs. They emerge from real users, doing unexpected things in unexpected combinations, at unexpected times. RUM makes those invisible paths visible. The synthesis pipeline makes them testable. And the closed loop ensures that what you learn in CI sharpens what you observe in production.
Your Tests Should Know What Your Users Know
The best test suite isn’t the one your engineers imagined. It’s the one your users wrote — without knowing it.
Every session captured by Cavisson’s RUM layer is a test case. Every invariant mined from your production traffic is an assertion your team didn’t have to write. Every property generated from your real value distributions is a failure mode discovered before a user hits it.
Cavisson gives you the RUM infrastructure to capture real user behaviour at scale, the synthesis pipeline to convert it into a living test suite, and the closed-loop architecture to feed results back into smarter observability. The gaps narrow. The edge cases surface before production does. The regressions stop shipping.
Ready to see it in action?
Book a Demo with Cavisson →
Discover how Cavisson can turn your production traffic — including every edge case, every negative scenario, and every path your test authors never imagined — into your most powerful quality asset. In days, not months.